Overview
I built a reinforcement-learning agent that converts arbitrary STL geometry into a Z-monotone (no undercuts) shape that can be milled with 2.5-axis CNC toolpaths. The pipeline voxelizes the input, computes Z-visibility/draft, non-monotonicity masks, EDT/thickness maps, and runs a PPO-trained 3D-CNN policy to make localized add/remove “brush” edits. I trained it at a low resolution in ~2 hours, but in practice it can be trained at any resolution with more time.
Learning Progress Visualization
Early training: agent learning material removalTrained agent: systematic non-monotonic removalThe video on the left shows the agent during early training, learning how to identify and remove material. The video on the right shows the trained agent systematically removing non-monotonic regions to ensure the part can be manufactured from the side. The rotation back and forth provides depth perception to better visualize the 3D voxel edits.
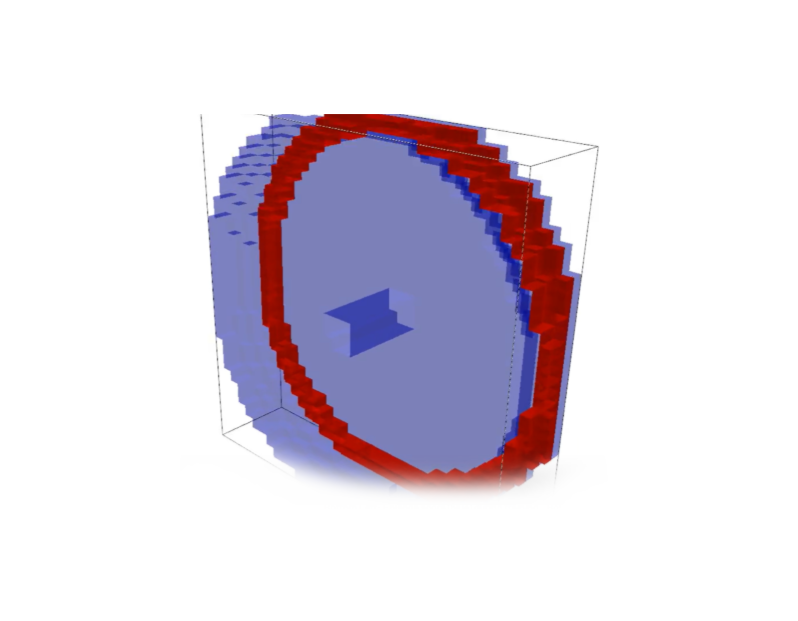
 Grooved pulley wheel used as toy problem for side machining
Grooved pulley wheel used as toy problem for side machining
RL Implementation
Formulation
Single-agent PPO (policy gradient with clipping) that samples a voxel index (x,y,z) from a categorical distribution over the grid; the environment interprets that index as a localized edit (add/remove/paint) with a small brush. Goal: eliminate non-monotone Z columns while minimizing geometric deviation and preserving manufacturability proxies.
Policy / Value Networks
Lightweight 3D-CNN stacks (Conv3d: 1->16->32->64 with ReLU).
- Actor: a 1x1x1 conv head produces per-voxel logits [DxHxW]; logits are flattened and softmaxed to a categorical over all voxels.
- Critic: identical trunk with a 1x1x1 value head, followed by global spatial mean to a scalar state-value.
On-Policy Training
GAE(lambda) with gamma=0.99, lambda=0.95; PPO clip epsilon=0.2; entropy bonus 0.01 to keep exploration over the 3D action space; Adam optimizers (lr = 3e-3); minibatch updates with shuffled indices, 10 epochs per update; critic MSE loss with 0.5 weight.
State & Device
POC uses a single-channel occupancy tensor (ready to extend to multi-channel features like masks/EDT); automatic CUDA usage when available; model checkpointing included.
Outcome
The agent learns to remove undercuts and enforce Z-monotonicity with minimal edits. Shown to be resolution agnostic. Showcases effective approach to learning geomerty manipulation and can be explaned upon for other use cases in the future.
Future Work
Current development focuses on extending the approach to handle 3-axis and 5-axis machining constraints as well as other geometric manipulation, multi-material parts, and assembly-level manufacturability. I’m also exploring transformer-based architectures for better long-range spatial reasoning.